



















Le data labeling est la pierre angulaire de l’apprentissage automatique et supervisé, principales formes d’intelligence artificielle. En étiquetant les données brutes, il permet aux algorithmes de les interpréter pour créer des modèles d’IA précis et fiables.
Le data labeling garantit la qualité des données, indispensable pour développer des systèmes capables de prendre des décisions complexes dans différents domaines. On peut citer la reconnaissance d’images et de vidéos et la compréhension du langage naturel.
Pourquoi le data labeling est essentiel
Le data labeling, ou étiquetage des données, consiste à annoter des données brutes (images, textes, vidéos, etc.) avec des étiquettes spécifiques qui permettent aux modèles IA de comprendre et d’apprendre à partir de ces données. Cela améliore considérablement la capacité des modèles à faire des prédictions précises et à prendre des décisions adéquates.
Fondements de l’apprentissage automatique et apprentissage supervisé
L’apprentissage supervisé (deep learning) est une méthode de machine learning (machine learning) où les modèles sont entraînés à partir de données étiquetées. Chaque étiquette associée à une donnée d’entraînement indique la réponse correcte ou la catégorie à laquelle appartient cette donnée. Par exemple, une image de chat serait étiquetée comme « chat ». Cela permet au modèle de reconnaître les caractéristiques associées à cette étiquette.
Pour que les modèles puissent apprendre efficacement, ils ont besoin de grandes quantités de données bien étiquetées. Des données de haute qualité et correctement annotées permettent aux modèles de généraliser leurs apprentissages à de nouvelles données non vues auparavant. Par conséquent, plus les étiquettes sont précises et représentatives, meilleure sera la capacité du modèle à faire des scénarios justes.
Influence sur la précision des modèles
La précision des modèles d’IA est directement influencée par la qualité des étiquettes de données utilisées lors de leur entraînement. Lorsque les données sont bien étiquetées, les modèles d’IA peuvent produire des résultats plus précis. À l’inverse, des étiquettes inexactes ou incohérentes peuvent entraîner des erreurs dans les prédictions.
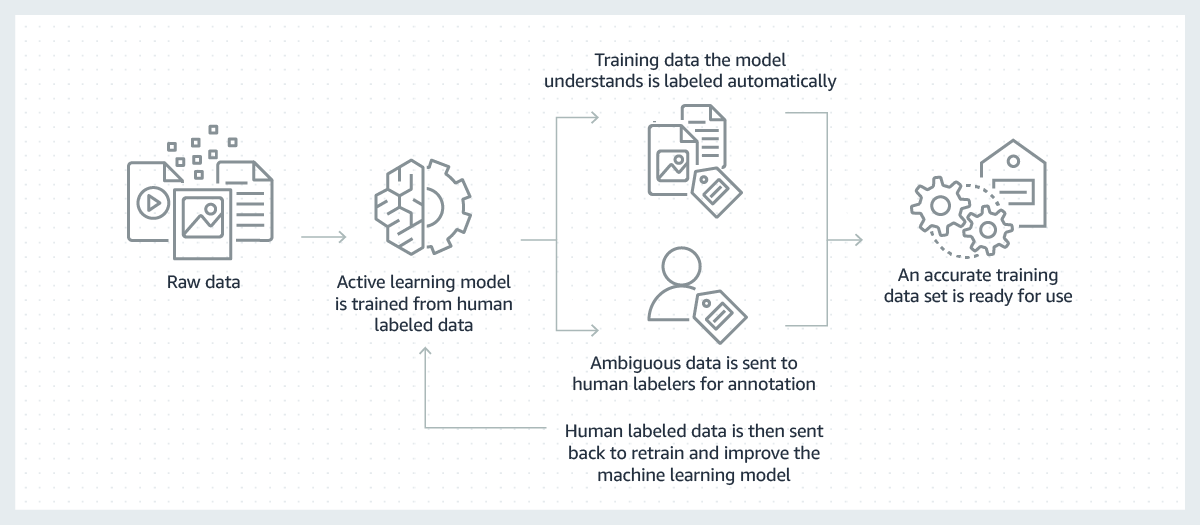
Le data labeling influence différents domaines comme la santé par exemple. Dans ce secteur, les images médicales doivent être précisément étiquetées pour aider au diagnostic. La conduite autonome est également un secteur où l’étiquetage de données est important. Les voitures autonomes doivent reconnaître des piétons et des panneaux de signalisation sans faire la moindre erreur.
Pour garantir la qualité des étiquettes, plusieurs pratiques peuvent être mises en œuvre :
- Utiliser l’expertise de professionnels pour étiqueter les données peut améliorer la précision des annotations grâce à leur connaissance du sujet.
- Effectuer des contrôles réguliers et des audits des étiquettes pour détecter et corriger les erreurs.
- Faire du Crowdsourcing, c’est-à-dire distribuer les tâches d’étiquetage à une large communauté en ligne.
Techniques et méthodes de data labeling
Il existe différentes approches manuelles ou automatiques pour étiqueter les données, chacune ayant ses avantages et ses inconvénients.
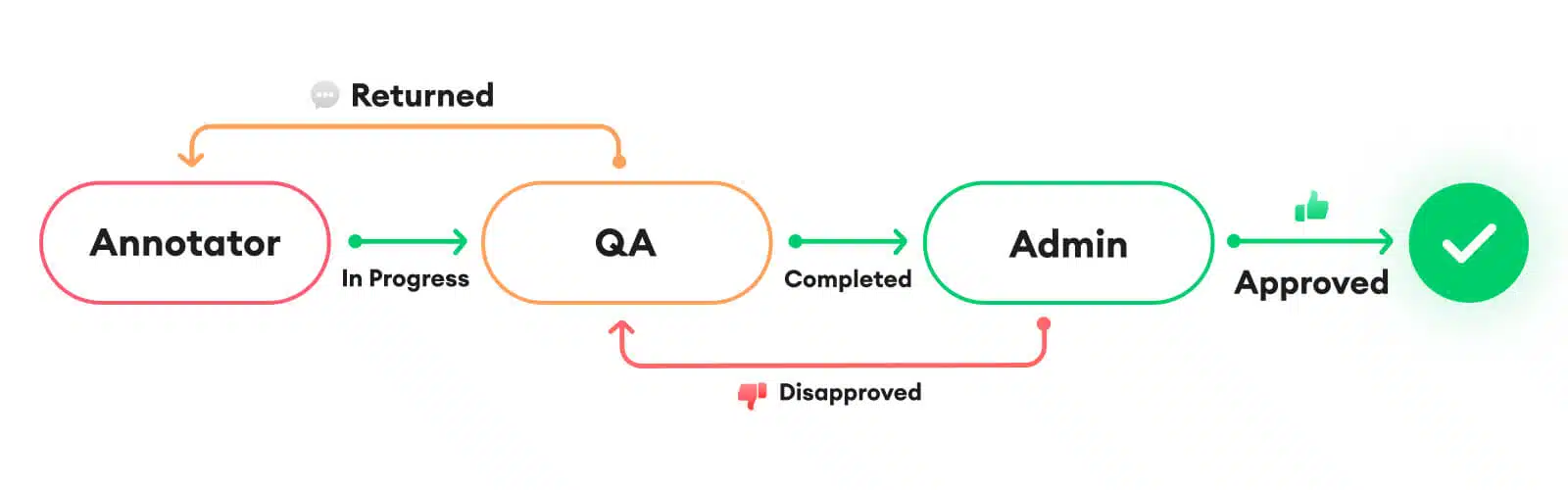
Approches manuelles de data labeling
Les méthodes manuelles de data labeling impliquent généralement des data labelers ou data scientists qui examinent et étiquettent les données. Ces approches sont souvent utilisées pour leur précision, car les humains peuvent comprendre les nuances et les différents contextes.
- Étiquetage par des experts : Impliquer des spécialistes du domaine pour annoter les données pour garantir une haute qualité des étiquettes. Ces experts possèdent des connaissances solides qui leur permettent de comprendre les données en détail et de fournir des annotations précises.
- Crowdsourcing : Utiliser une grande communauté en ligne pour annoter les données pour accélérer l’étiquetage. Des plateformes comme Amazon Mechanical Turk permettent de diviser les tâches d’annotation entre de nombreux travailleurs. Bien que cette méthode soit rapide et économique, elle peut nécessiter des mécanismes de contrôle de qualité supplémentaires pour assurer la précision des étiquettes.
- Équipe dédiée d’annotateurs : Certaines entreprises disposent d’équipes internes d’annotateurs formés spécifiquement pour le data labeling. Cette méthode permet un contrôle direct sur le processus d’étiquetage et garantit une qualité constante, bien que cela puisse être coûteux en termes de temps et de ressources. Les annotateurs doivent comprendre les critères d’étiquetage et les objectifs des projets pour assurer des annotations cohérentes.
Automatisation du data labeling
Les techniques d’automatisation du data labeling utilisent des algorithmes et des outils d’apprentissage automatique pour étiqueter les données de manière plus efficace et à grande échelle.
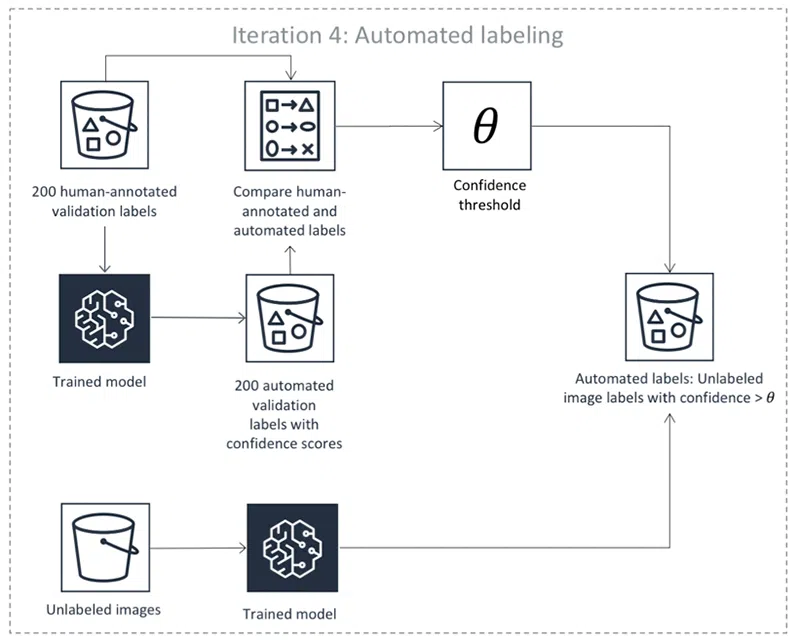
- Utilisation de modèles pré-entraînés : Les algorithmes d’apprentissage automatique peuvent être pré-entraînés sur des jeux de données similaires pour étiqueter automatiquement de nouvelles données. Ces modèles utilisent des techniques telles que les réseaux neuronaux, les modèles de Markov cachés et les N-grammes pour générer des annotations.
- Techniques de semi-supervision : Les approches semi-supervisées combinent des données étiquetées et non étiquetées pour améliorer l’efficacité de l’étiquetage automatique. Les algorithmes apprennent à partir d’un petit ensemble de données étiquetées et appliquent ensuite ces connaissances pour étiqueter automatiquement de plus grandes quantités de données non étiquetées.
- Outils d’annotation automatisés : Des logiciels spécialisés, tels que les plateformes d’annotation de données, offrent des fonctionnalités d’automatisation pour aider les data labelers humains. Ces outils peuvent suggérer des étiquettes potentielles que les annotateurs peuvent ensuite valider ou corriger.
- Apprentissage actif : Cette méthode implique des algorithmes qui identifient les données les plus ambiguës ou incertaines et les présentent aux annotateurs humains pour une vérification. Cela optimise le processus d’étiquetage en se concentrant sur les cas où l’intervention humaine est nécessaire.
L’automatisation du data labeling peut considérablement améliorer l’efficacité et réduire les coûts, mais elle nécessite une supervision humaine pour garantir la qualité et la précision des étiquettes.
Algorithmes utilisés dans l’étiquetage des données
Le processus de data labeling peut être optimisé par l’utilisation d’algorithmes complexes. Ces algorithmes permettent d’améliorer la précision des annotations automatisées.
Algorithmes de classification
Les algorithmes de classification jouent un rôle clé dans l’étiquetage des données . Ils attribuent des étiquettes à des ensembles de données. Voici quelques-uns des algorithmes couramment utilisés :
- Arbres de décision : Ces algorithmes créent un modèle de décisions basé sur des caractéristiques d’entrées pour prédire l’étiquette d’une donnée. Ils sont particulièrement utiles pour leur simplicité et leur capacité à gérer des données catégorielles et continues.
- k-plus proches voisins (k-NN) : Cet algorithme attribue une étiquette à une donnée en fonction des étiquettes des k données les plus proches dans l’espace des caractéristiques. Il est simple et efficace, surtout pour les petites quantités de données.
- Réseaux de neurones : Utilisés principalement dans les algorithmes d’apprentissage profond, les réseaux de neurones sont constitués de couches de nœuds interconnectés qui traitent les données d’entrée pour produire une sortie. Ils sont puissants pour la classification des données complexes et les tâches de reconnaissance de formes.
- Diarisation du locuteur : Ils identifient et segmentent la parole par identité de locuteur pour aider à distinguer les différents intervenants dans une conversation. Cela est particulièrement utile dans des applications comme les transcriptions automatiques.
- N-grammes : Modèles de langue qui attribuent des probabilités aux phrases ou expressions et améliorent la reconnaissance et l’exactitude des annotations.
Algorithmes de détection d’objets
Les algorithmes de détection d’objets sont utilisés pour localiser et classer plusieurs objets dans des images ou des vidéos. Parmi les plus connus, on trouve :
- YOLO (You Only Look Once) : Cet algorithme divise une image en une grille et prévoit les probabilités de différentes classes d’objets et leurs positions dans chaque cellule de la grille. YOLO est réputé pour sa rapidité et sa précision en temps réel.
- SSD (Single Shot MultiBox Detector) : Comme YOLO, SSD détecte les objets en une seule étape, sans nécessiter de phase de proposition de région comme dans d’autres algorithmes plus anciens. Il génère une série de boîtes englobantes avec des scores de classe pour chaque image, permettant une détection rapide et précise.
Techniques de sélection active
Les techniques de sélection active sont utilisées pour optimiser le processus de data labeling. Elles permettent aux modèles d’apprentissage automatique de choisir les données les plus utiles à étiqueter. Voici quelques-unes des méthodes courantes :
- Échantillonnage basé sur l’incertitude : Cette méthode sélectionne les données pour lesquelles le modèle est le plus incertain, c’est-à-dire celles qui ont des prédictions proches de la frontière de décision. Cela permet de concentrer l’effort d’étiquetage sur les exemples les plus difficiles.
- Échantillonnage basé sur la diversité : Cette technique sélectionne des exemples diversifiés pour étiquetage, afin de couvrir une large gamme de cas possibles. Cela aide à créer un ensemble de données d’entraînement plus représentatif et à réduire les biais.
- Échantillonnage basé sur le rendement : Ici, les données sont choisies en fonction de leur impact potentiel sur la performance du modèle. Les exemples qui devraient améliorer le plus le modèle une fois étiquetés sont sélectionnés en priorité.
En combinant ces algorithmes et techniques, le processus de data labeling devient plus efficace, précis et adapté aux besoins des différents modèles d’apprentissage automatique. Les algorithmes de classification et de détection d’objets automatisent le marquage des données, tandis que les techniques de sélection active optimisent le processus en se concentrant sur les données les plus pertinentes à étiqueter.
Enjeux éthiques du data labeling
Le data labeling, bien que fondamental pour le développement des modèles d’apprentissage automatique, soulève plusieurs questions éthiques importantes. Ces enjeux concernent principalement la confidentialité, la sécurité et la qualité des données.
Confidentialité des données
Lors de l’annotation des données, les data labelers peuvent avoir accès à des informations sensibles ou personnelles. Il est important de garantir que ces informations sont protégées et que la vie privée des individus soit respectée. Les entreprises doivent mettre en place des politiques strictes de gestion des données avec l’anonymisation des données sensibles et l’utilisation de plateformes sécurisées pour l’étiquetage.
- Anonymisation des données : Avant d’être soumises aux annotateurs, les données doivent être anonymisées pour supprimer toute information identifiable. Cela réduit le risque de violation de la vie privée et protège les individus concernés.
- Accès restreint : Limiter l’accès aux données étiquetées à un nombre restreint de personnes et utiliser des accords de confidentialité peut également aider à maintenir la confidentialité des données.
Sécurité des données
Les données étiquetées doivent être protégées contre les accès non autorisés, les modifications malveillantes et les pertes accidentelles. Des mesures de sécurité robustes sont nécessaires pour garantir l’intégrité et la confidentialité des données tout au long du processus d’étiquetage.
- Chiffrement des données : Utiliser des techniques de chiffrement pour protéger les données lors de leur stockage et de leur transmission. Cela empêche les accès non autorisés et les interceptions malveillantes.
- Contrôles d’accès : Implémenter des contrôles d’accès rigoureux pour s’assurer que seules les personnes autorisées peuvent accéder aux données étiquetées. Cela inclut l’utilisation de systèmes d’authentification forte et de surveillance des accès.
Qualité des données
Des données mal étiquetées peuvent introduire des biais, réduire la précision des modèles et entraîner des décisions incorrectes. Il est donc nécessaire de maintenir des normes élevées de qualité lors du data labeling.
- Contrôle de la qualité : Mettre en place des processus de contrôle de qualité pour vérifier l’exactitude et la cohérence des étiquettes. Cela peut inclure des revues par des pairs, des audits réguliers et l’utilisation d’outils d’évaluation automatique.
- Formation des data labelers : Fournir une formation adéquate aux annotateurs pour s’assurer qu’ils comprennent les critères d’étiquetage et peuvent effectuer leur travail avec précision. Une bonne formation réduit les erreurs et améliore la cohérence des étiquettes.
Biais et équité
Le data labeling peut également introduire des biais dans les modèles d’IA si les données ne sont pas représentatives ou si les étiquettes reflètent des préjugés humains. Il faut identifier et corriger ces biais pour garantir que les modèles d’IA restent équitables et justes.
- Diversité des annotateurs : Engager des annotateurs de diverses origines et perspectives peut aider à réduire les biais et à garantir que les données étiquetées sont représentatives de la population cible.
- Évaluation des biais : Utiliser des techniques pour identifier et évaluer les biais dans les données étiquetées, et ajuster les processus d’étiquetage en conséquence.
Les enjeux éthiques du data labeling sont complexes et nécessitent une attention rigoureuse pour garantir que les données sont étiquetées de manière confidentielle, sécurisée et de haute qualité. Les entreprises doivent être claires sur la manière dont les données sont collectées, étiquetées et utilisées. En abordant ces défis de manière proactive, les entreprises peuvent développer des modèles d’IA plus fiables, précis et équitables.
Si le sujet de l’IA vous intéresse, je vous invite fortement à parcourir ces articles :