



















« Data Science » est devenu un concept à la mode, employé souvent à tort et à travers pour décrire à peu près tout et n’importe quoi. On pense souvent que la Data Science est inséparable du Big Data, que la Data Science est l’art et la manière d’analyser des volumes énormes de données. C’est en bonne partie inexact. La question du volume est secondaire. Une autre erreur souvent commise consiste à associer systématiquement la Data Science et le Machine Learning. On n’a pas attendu le Machine Learning pour faire de la modélisation mathématique et statistique. Ce sont toutes ces confusions que nous allons essayer de lever dans les paragraphes qui suivent.
Avant de commencer, un petit rappel sémantique. Dans Data Science, cela n’aura échappé à personne, il y a « Science ». La Data Science se base en effet sur des méthodes scientifiques, sur des savoirs mathématiques et statistiques, et pas uniquement sur de l’empirisme et de l’intuition. Dans Data Science, il y a aussi Data, c’est-à-dire « données ». Sur ce point, il faut bien comprendre que « données » et « information » ne sont pas synonymes. Les données sont des éléments bruts et inorganisés qui ont besoin d’un traitement pour acquérir du sens. La donnée, non travaillée, laissée à son chaos, ne sert à rien. L' »information », c’est de la donnée organisée, traitée, structurée et porteuse d’une signification. Tout l’art du Data Scientist est de transformer des données brutes en informations exploitables par l’entreprise.
Ces quelques remarques et précisions étant faites, nous pouvons commençons à essayer de percer les secrets de cette nouvelle discipline, clairement fascinante et promise à un bel avenir.
Sommaire
Depuis quand parle-t-on de Data Science ? Et pourquoi ?
Il y a encore 5 ou 6 ans, personne ou presque ne connaissait cette discipline et ceux qui la connaissaient ne la prenaient pas toujours très au sérieux. Comme le montre le graphique ci-dessous (merci Google Trends), l’utilisation des termes « Data Science » et « Data Scientist » décolle franchement à partir de 2012. D’ailleurs, on parle beaucoup plus souvent de « Data Science » que de « Data Scientist ».
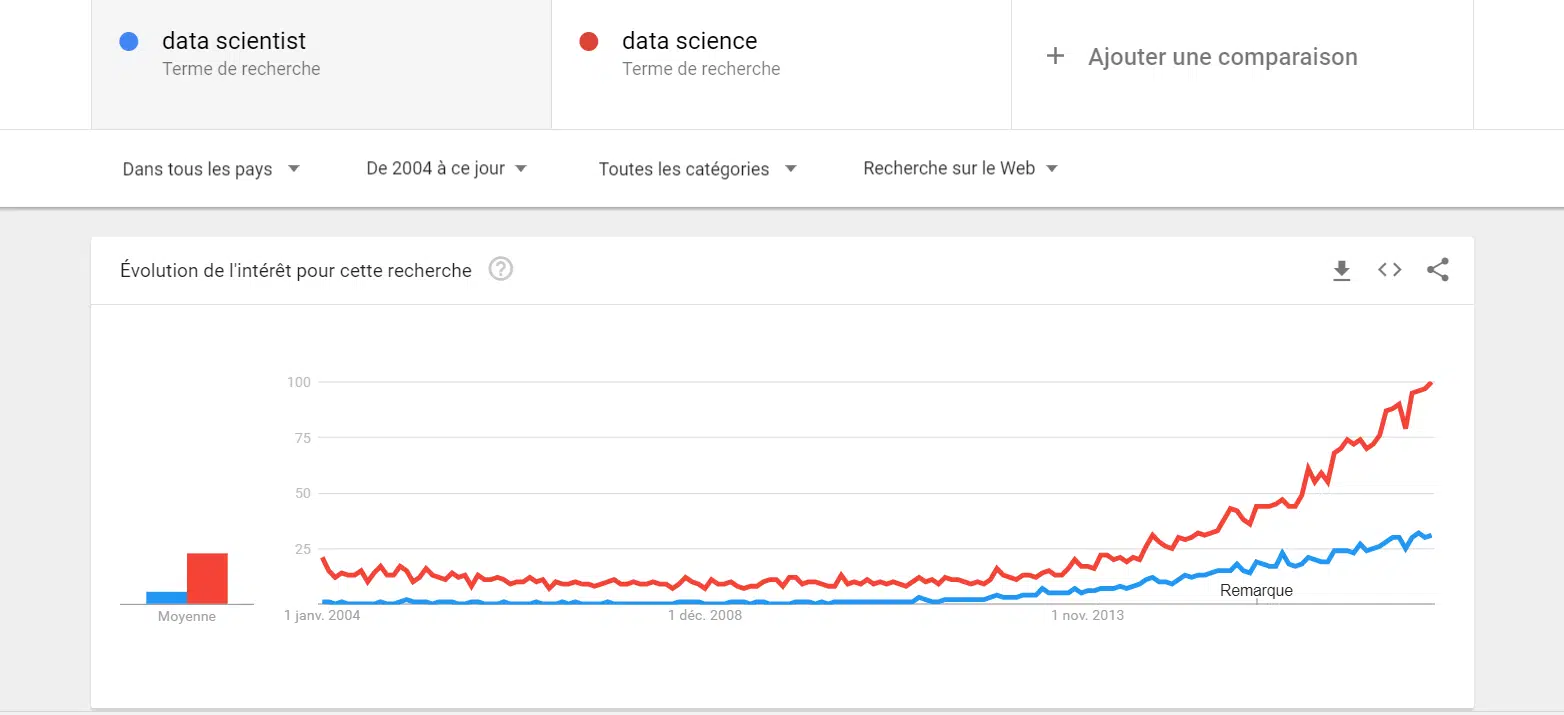
Le deuxième constat, c’est que malgré tout on parlait de Data Science avant 2008, et même en 2004 (malheureusement, il n’est pas possible via Trends de remonter avant 2004…) ! Donc, ceux qui vous disent que la Data Science est une discipline très récente se trompent. La Data Science est une discipline plus ancienne qu’on ne le pense. En un sens, cette discipline a toujours existé. Sauf qu’il y a 30 ans, on ne parlait pas de « Data Science », le terme n’existait pas.
Pourquoi parle-t-on autant de Data Science depuis ces dernières années ? A l’origine, les données dont disposaient les entreprises étaient essentiellement structurées et en nombre très limité. Aujourd’hui à l’inverse, les données sont largement non-structurées ou semi-structurées. Comme le montre le graphique suivant, on estime qu’en 2010, les données non structurées représenteront plus de 80% des données collectées par les entreprises.

Ces données proviennent de sources très diverses et très hétérogènes entre elles. Les outils basiques de BI ne sont plus capables de traiter cet énorme volume de données et surtout cette variété considérable de données. C’est la raison pour laquelle nous avons besoin aujourd’hui d’utiliser des outils d’analyse et des algorithmes plus complexes et plus avancés pour retirer des « insights » de cette masse de données brutes. Mais ce n’est pas la seule raison pour lesquelles la Data Science est devenue en un sens un terme « populaire » (même si peu de personnes comprennent vraiment de quoi il s’agit !). L’autre raison de l’essor de la Data Science, c’est l’explosion des cas d’usage. En voici trois :
- Qu’est-ce qui se passerait si vous pouviez comprendre précisément les besoins de vos clients grâce aux données dont vous disposez déjà sur eux (comme par exemple leur historique de navigation, leur historique d’achat, leur âge, leurs revenus, etc.) ? Vous avez déjà ses données dans votre système d’information. Mais désormais, avec l’augmentation du volume de données à disposition, vous pouvez faire tourner des modèles de manière beaucoup plus efficace que par le passé et faire de la recommandation avec beaucoup plus de pertinence. Avec à la clé, plus de chiffre d’affaires et plus de bénéfices pour votre entreprise. La recommandation marketing est l’un des grands champs d’application de la Data Science.
- Prenons un autre cas d’usage de la Data Science, un autre exemple de l’utilisation de cette « science » dans la prise de décision. Imaginez une voiture capable de vous conduire d’elle-même à votre domicile ? Les voitures autonomes collecte de la donnée à partir de capteurs sensibles (des radars, des caméras, des lasers) pour créer une carte de l’environnement. En se basant sur les données collectées en temps réel, la voiture peut prendre des décisions elles-mêmes. Par exemple, accélérer, ralentir, dépasser, négocier un virage, etc. Le tout en se basant sur des algorithmes de machine learning. L’essor des voitures autonomes a un rôle dans la popularisation de la Data Science.
- Prenons un dernier exemple. Celui de l’analyse prédictive. Et plus spécifiquement, l’analyse prédictive appliquée aux prévisions météorologiques. Les données en provenance des avions, des bateaux, des radars et des satellites peuvent être collectées et analysées pour construire des modèles. Avec modèles, non seulement on pourrait prédire le temps qu’il fera dans les jours à venir, mais aussi la récurrence des catastrophes naturelles. Cette application de la Data Science pourrait potentiellement sauver des dizaines de vies.
Les domaines d’application de la Data Analyse sont très nombreux. Cette infographie permet d’en prendre conscience :
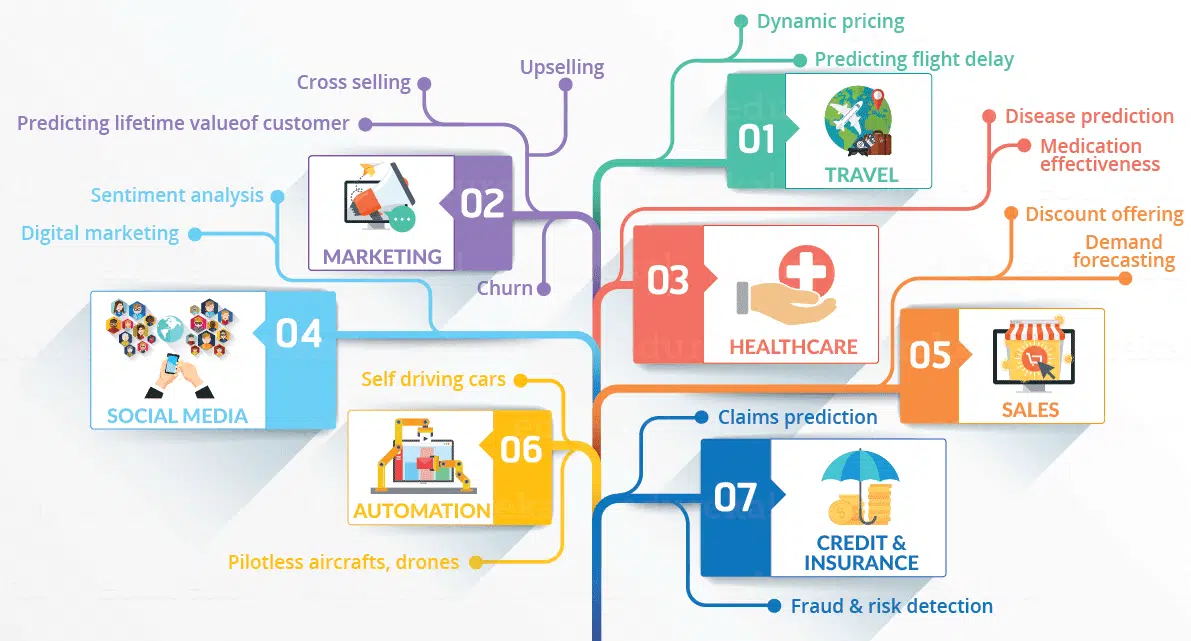
De plus en plus de domaines ont besoin de la Data Science pour se développer. On n’a pas donc clairement pas fini d’entendre parler de cette discipline. Maintenant que nous savons pourquoi la Data Science s’est « imposée », essayons de comprendre comment ça marche !
Découvrez notre article complet sur l’intelligence artificielle (définition & applications au marketing digital).
Les fondamentaux pour comprendre ce qu’est la Data Science [Définition]
Le mot de « Data Science » est devenu assez commun. Mais de quoi s’agit-il concrètement ? Quelles sont les compétences requises pour devenir Data Scientist ? Quelle est la différence entre la Business Intelligence et la Data Science ? Comment s’opèrent la prise de décision et les prédictions en Data Science ? Voici quelques unes des questions auxquelles nous allons essayer de donner des réponses.
Commençons par la base. Quelle est la définition de la « Data Science » ? On en a déjà touché quelques mots en introduction. Très schématiquement, on pourrait dire que la Data Science mélange des outils, des algorithmes et des principes de machine learning avec pour objectif de découvrir des patterns cachés à partir de données brutes. Mais en quoi le travail du Data Scientist est différent de ce que font les analystes de données depuis des années ? Toute la différence entre les deux se résume à la différence qu’il y a entre expliquer et prédire.
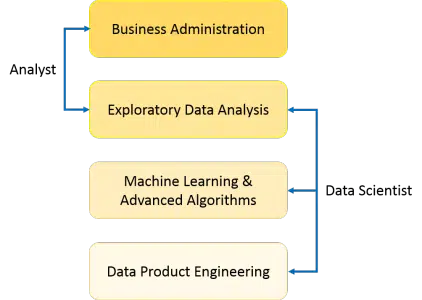
Le Data Analytist explique ce qui arrive en explorant les données. Pour découvrir des insights, le Data Scientist, quant à lui, ne se contente pas d’une analyse exploratoire, il utilise en plus des algorithmes avancés de machine learning pour identifier les occurrences de tel ou tel événement dans le futur. Un Data Scientist regarde les données sous plusieurs angles, dont certains inconnus jusque là. La Data Science est essentiellement utilisée pour prendre des décisions et faire des prédictions en se basant de l’analyse prédictive causale, de l’analyse normative et du machine learning. Reprenons chacun de ces termes :
- L’analyse prédictive causale (Predictive causal analytics). Si vous souhaitez un modèle permettant de prédire la probabilité d’occurrence d’un événement dans le futur, vous devez faire de l’analyse prédictive causale. Si votre activité consiste à prêter de l’argent, savoir si vos clients vous rembourseront dans les temps est quelque chose qui vous préoccupe. Si vous êtes dans ce cas, vous pourriez construire un modèle pour réaliser des analyses prédictives et prédire si vos clients vous régleront à temps, en vous basant sur leur historique de paiement. L’analyse prédictive est une dimension importante de la Data Science.
- L’analyse normative (ou « Prescriptive analytics »). Si vous souhaitez un modèle qui a l’intelligence de prendre des décisions tout seul et la capacité de les modifier en fonction de paramètres dynamiques, vous aurez certainement besoin de ce qu’on appelle l’analyse normative. Ce domaine est relativement récent. L’objectif est de générer des recommandations. En d’autres termes, le modèle ne se contente pas de prédire mais suggère plusieurs actions possibles avec leurs résultats prévisibles. Le meilleur exemple d’application de l’analyse normative, ce sont les voitures autonomes. Les données collectées par les véhicules peuvent être utilisées pour « entraîner » les voitures autonomes. Vous pouvez faire tourner des algorithmes sur ces données pour y apporter de l’intelligence. Le résultat des analyses est ensuite utilisé pour prendre des décisions : tourner, accélérer, ralentir, etc.
- Le machine learning (pour la prise de décisions). Si vous avez à votre disposition les données transactionnelles d’une entreprise dans la finance et que vous avez besoin de construire un modèle pour déterminer les futures tendances, alors le machine learning est sans doute la meilleure solution. Il s’agit dans ce cas de ce qu’on appelle l’apprentissage supervisé. « Supervisé » dans le sens où vous avez déjà à l’avance la donnée qui sera utilisée pour entraîner les machines. Par exemple, vous vous pouvez entraîner un modèle de détection des fraudes en utilisant l’historique des achats frauduleux.
- Le machine learning (pour découvrir des patterns). Si vous ne disposez à l’avance pas des paramètres nécessaires pour faire les prédictions (comme dans le cas précédent), vous devez trouver des patterns ( = motifs) cachés en explorant la base de données. C’est ce qu’on appelle des modèles non supervisés. L’apprentissage se fait « en roue libre », sans guidage humain. La plupart du temps, on utilise un algorithme de regroupement (clustering) pour découvrir les motifs cachés. Prenons un exemple. Vous êtes une entreprise de téléphonie. Vous avez besoin de créer un réseau de pylônes dans une région. Vous pouvez utiliser la technique du regroupement pour identifier le meilleur placement des pylônes (= celui permettant aux utilisateurs du réseau d’obtenir le meilleur signal). C’est un exemple parmi tant d’autres…Sur la différence entre apprentissage supervisé et apprentissage non supervisé, nous vous invitons à lire cet article, très clair et très intéressant.
Découvrez notre guide complet sur la gestion de projet Lean – Définitions et Bonnes pratiques.
L’infographie ci-dessous permet de bien comprendre les différences entre Data Analyse et Data Science, mais aussi leurs recoupements sur certains aspects. En effet, la Data Analyse n’est pas uniquement dans la description. Elle intègre une dimension prédictive jusqu’à un certain point (des corrélations). Dans la Data Science, il y a beaucoup d’analyse prédictive et beaucoup de machine learning. Même si, encore une fois, la Data Science est très loin de se réduire au machine learning.
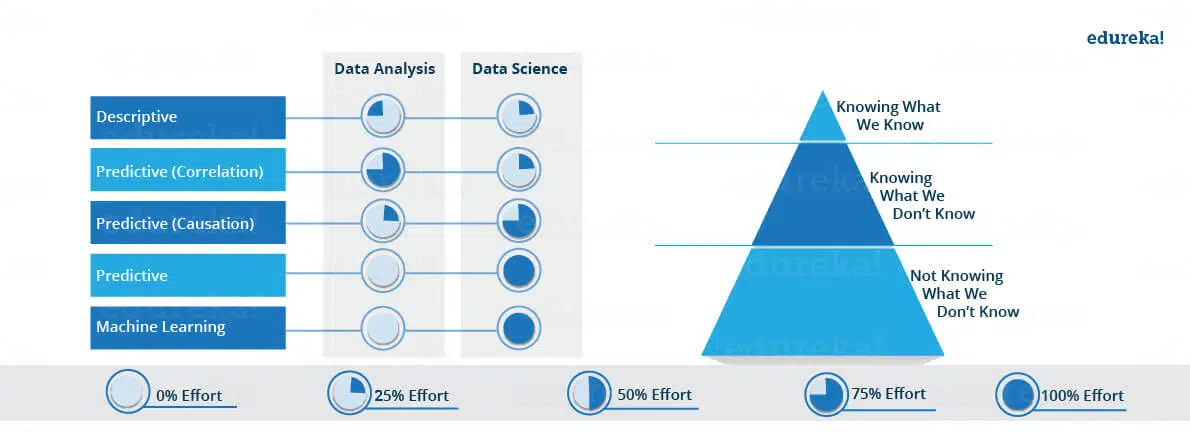
S’il est important de distinguer Data Analyse et Data Science, il l’est tout autant de ne pas confondre Data Science et Business Intelligence. On parle clairement de deux choses différentes :
- La BI est l’activité qui consiste à analyser les données existantes de l’entreprise pour dégager des insights destinés à aider les décideurs dans leur prise de décision. La BI utilise des données externes et internes, les prépare, exécute des requêtes sur ces données et crée des tableaux de bord destinés aux managers ou décideurs. La BI peut aussi être utilisée pour faire des études d’impact.
- La Data Science est une approche beaucoup plus orientée sur la prédiction. Il s’agit essentiellement d’explorer, d’analyser les données passées et présentes pour prédire des résultats futurs. La Data Science permet de répondre à des questions ouvertes (« Comment…? », « Qu’est-ce que…? »).
Découvrez où trouver, et comment sélectionner un bon consultant web.
Voici un tableau récapitulant les principales différences entre les deux activités :
| Business Intelligence (BI) | Data Science | |
|---|---|---|
| Sources de données | Données structurées (SQL, Entrepôt de données) | Données structurées et non structurées (logs, cloud data, SQL, NoSQL, text) |
| Approche | Statistiques et visualisation | Statistiques, Machine Learning, Graph analysis, Neuro-linguistic programming (NPL) |
| Focus | Passé et présent | Présent et futur (prédictif) |
| Outils | Pentaho, Microsoft BI, QlikView, R | RapidMiner, BigML, Weka, R |

Le cycle de vie d’un projet en Data Science
Dans un projet de Data Science, une erreur assez commune consiste à se précipiter tête baissée dans la collecte et l’analyse de données, sans avoir au préalable pris suffisamment de temps pour définir les besoins et problématiques business. Pour réussir un projet de Data Science, il est nécessaire de bien suivre toutes les étapes. Ce schéma résume les différentes étapes du cycle de vie d’un projet en Data Science.
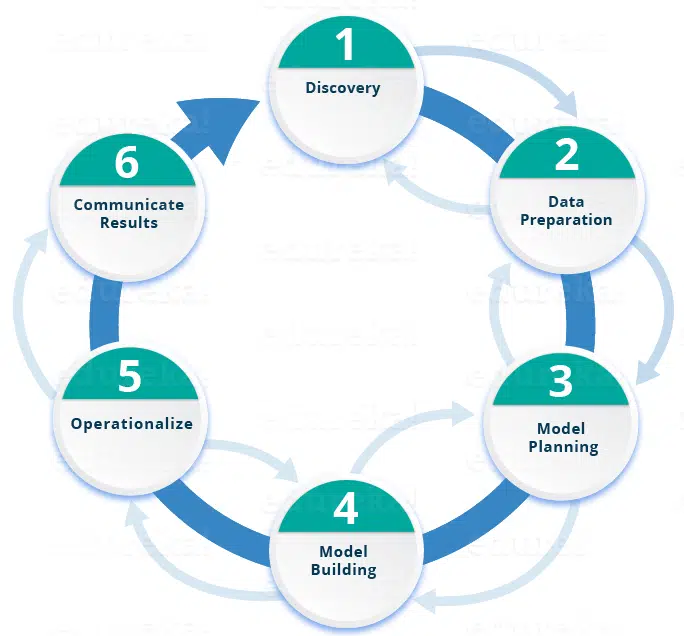
On peut décrire ces étapes une à une.
Etape #1 Discovery (Découverte)
Avant de commencer un projet de Data Science, il est important de comprendre les diverses spécifications, les besoins, les priorités…sans oublier la question budgétaire. Vous devez commencer par vous poser les bonnes questions. Vous demander par exemple si avez les ressources nécessaires pour mener à bien le projet, que ce soit d’un point de vue humain, technique ou data. Dans cette phase initiale, vous devez aussi cadrer la problématique business et formuler les hypothèses à tester.
Découvrez notre guide complet sur le scrum et de la gestion de projet « agile ».
Etape #2 Data preparation (Préparation des données)
La préparation des données est une étape indispensable à l’analyse. Vous devez charger toutes vos données dans un outil d’analyse (type Dataiku par exemple), qui vous servira de « bac à sable » tout au long du projet. Vous avez besoin de preprocesser et conditionner les données avant de commencer le travail de modélisation. Vous devrez suivre une procédure « ETLT »(Extraire, Transformer, Charger et Transformer) pour intégrer vos données dans le bac à sable.

Vous pouvez utiliser R pour le nettoyage des données, la transformation et la visualisation. Cela vous permettra de mettre au jour les valeurs aberrantes et d’établir des relations entre variables. Une fois que vous aurez nettoyé et préparé les données, vous pourrez commencer l’analyse exploratoire.
Etape #3 Model Planning (Déterminer le modèle)
Lors de cette phase, vous devez déterminer les méthodes et les techniques à appliquer pour établir des relations entre les variables. Ces relations serviront de base aux algorithmes que vous mettrez en place dans l’étape suivante. Pour cela, vous devez appliquer ce qu’on appelle l’analyse de donnée exploratoire (en anglais : Exploratory Data Analysis, ou EDA), en utilisant des formules statistiques et des outils de visualisation. Il existe un certain d’outils permettant de faire du model planning.

- R offre tout ce qu’il faut pour faire de la modélisation et propose un environnement idéal pour construire des modèles interprétatifs.
- SQL Analysis services, proposé par Microsoft, qui permet de faire de l’analyse dans les bases de données, avec des fonctions de data mining et des modèles prédictifs basiques.
- SAS/ACCESS, qui peut être utilisé pour accéder à des données d’Hadoop et qui est utilisé pour créer des modèles d’organigramme réutilisables.
Après avoir exploré vos données, dégagé des insights et déterminé les algorithmes à utiliser, la prochaine étape consiste à appliquer l’algorithme et à construire le modèle.
Etape #4 Model Building (Construire le modèle)
Dans cette étape, vous allez devoir développer vos jeux de données. Il y a deux possibilités. Soit vous estimez que les outils que vous utilisez actuellement sont suffisants pour faire tourner les modèles. Soit vous estimez que vous avez besoin d’un environnement plus robuste. Vous allez devoir analyser plusieurs techniques de learning pour construire le modèle : le techniques de classification, d’association, de regroupement. Voici une série d’outils permettant de construire votre modèle :

Etape #5 Operationalize (Mettre en oeuvre)
La phase de mise en oeuvre consiste à créer les rapports, les briefs, les documents techniques et relatifs à la programmation. Dans certains cas, un projet pilote peut aussi être implémenté dans un environnement de production en temps réel. Cela permet de se faire une bonne idée de la performance du modèle avant son déploiement.
Etape #6 Communicate results (Communiquer les résultats)
La dernière étape consiste à évaluer la performance du modèle, à vérifier si les objectifs de départ ont été atteints ou non, à tirer les principales conclusions, à les communiquer aux parties prenantes et à déterminer in fine si le projet est concluant ou non.
Découvrez 10 conseils illustrés pour réussir votre pitch investisseurs.
Cas pratique : la prévention des diabètes
Pour donner plus de chair à notre propos, rien de tel que de prendre un exemple très concret de projet. Dans cette étude de cas, nous allons vous présenter un projet dont l’objectif est de prédire l’apparition des diabètes afin d’améliorer la prévention. Nous allons reprendre les 6 étapes décrites plus haut.
Etape #1
Dans la première étape, il faut collecter les données relatives à l’historique médical des patients. On peut partir de l’échantillon de données suivant :
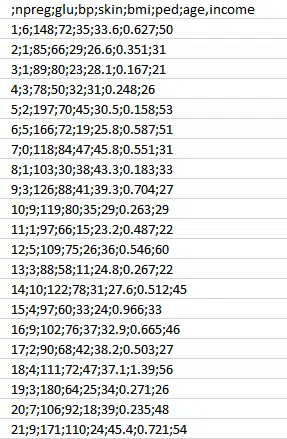
Voici les attributs utilisés :
- npreg – Le nombre de grossesses
- glucose – La concentration de glucose dans le plasma
- bp – La pression sanguine
- skin – L’épaisseur du pli cutané
- bmp – L’indice de masse corporelle
- ped – Antécédents diabétiques
- age – Age
- income – Revenus
Etape #2
Maintenant que nous avons les données, il faut les nettoyer et les préparer en vue de l’analyse exploratoire. Car, en l’état actuel, les données utilisées comportent des incohérences : des valeurs manquantes, des colonnes vides, des formats incorrects, etc. Dans l’image ci-dessous, les données ont été organisées dans un tableau, pour y voir plus clair.
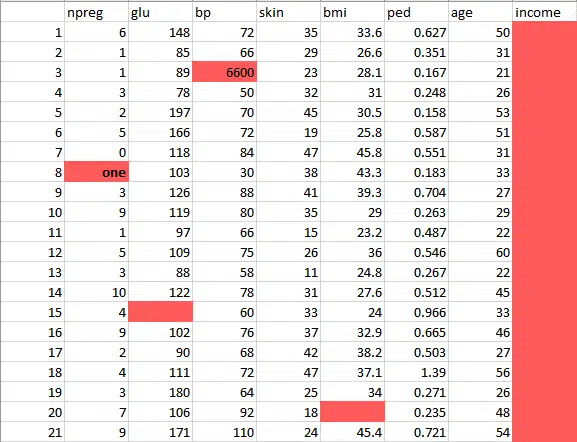
Plusieurs incohérences sautent aux yeux. Ce sont les zones rouges :
- Dans la colonne npreg, on a « one » au lieu de « 1 ».
- Dans la colonne bp, une des valeurs est complètement aberrante : « 6 600 ».
- La colonne « Income » est complètement vierge. Sans compter qu’on voit mal en quoi cette variable pourrait aider à prédire les diabètes. Le mieux est de supprimer purement et simplement la colonne.
Après avoir fait quelques nettoyages, les données sont prêtes à être analysées.
Etape #3
On peut, à partir des données préparées, réaliser quelques analyses :
- Dans un premier temps, il faut charger les données dans un bac à sable et appliquer des fonctions statistiques. Par exemple, R a une fonction comme « describe » qui donne le nombre de valeurs manquantes et de valeurs uniques. On peut aussi utiliser la fonction summary qui permet d’obtenir des statistiques générales : valeur maximale, valeur minimale, valeur médiane, rang, etc.
- On peut ensuite utiliser des techniques de visualisation (histogrammes, graphes linéraires, etc.) pour avoir un meilleur aperçu de la distribution des données.
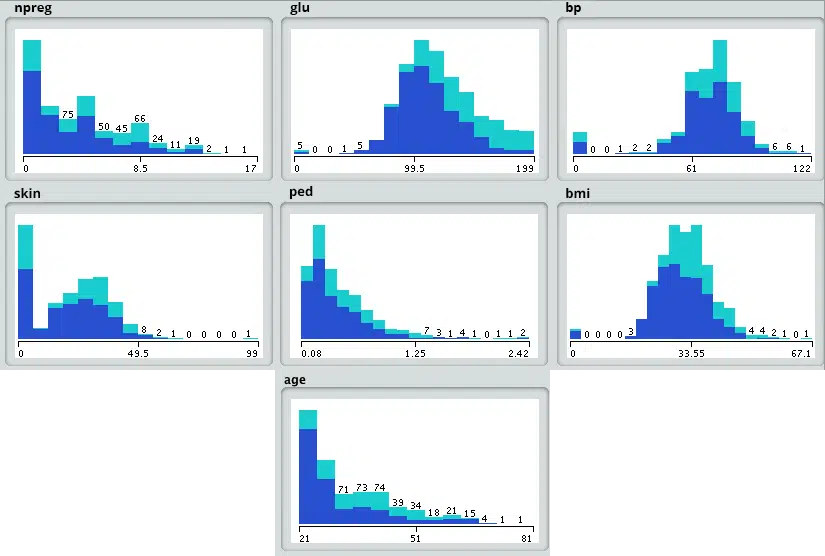
Etape #4
La précédente étape a permis de dégager des insights. Maintenant, pour ce type de problématique, il peut être intéressant d’utiliser un arbre de décision. Comme on a déjà à disposition la plupart des attributs importants (npreg, bmi…), on peut utiliser la technique d’apprentissage non-supervisée pour construire le modèle. L’arbre de décision permet de prendre tous les attributs en compte en une seule fois – ceux qui ont une relation linéaire comme ceux qui ont une relation non-linéaire. Dans ce cas, on a une relation linéaire entre npreg et age, et une relation non-linéaire entre npreg et ped. Il est possible d’utiliser différentes combinaisons d’attributs pour produire plusieurs arbres – l’idée étant à la fin d’implémenter le plus efficace.
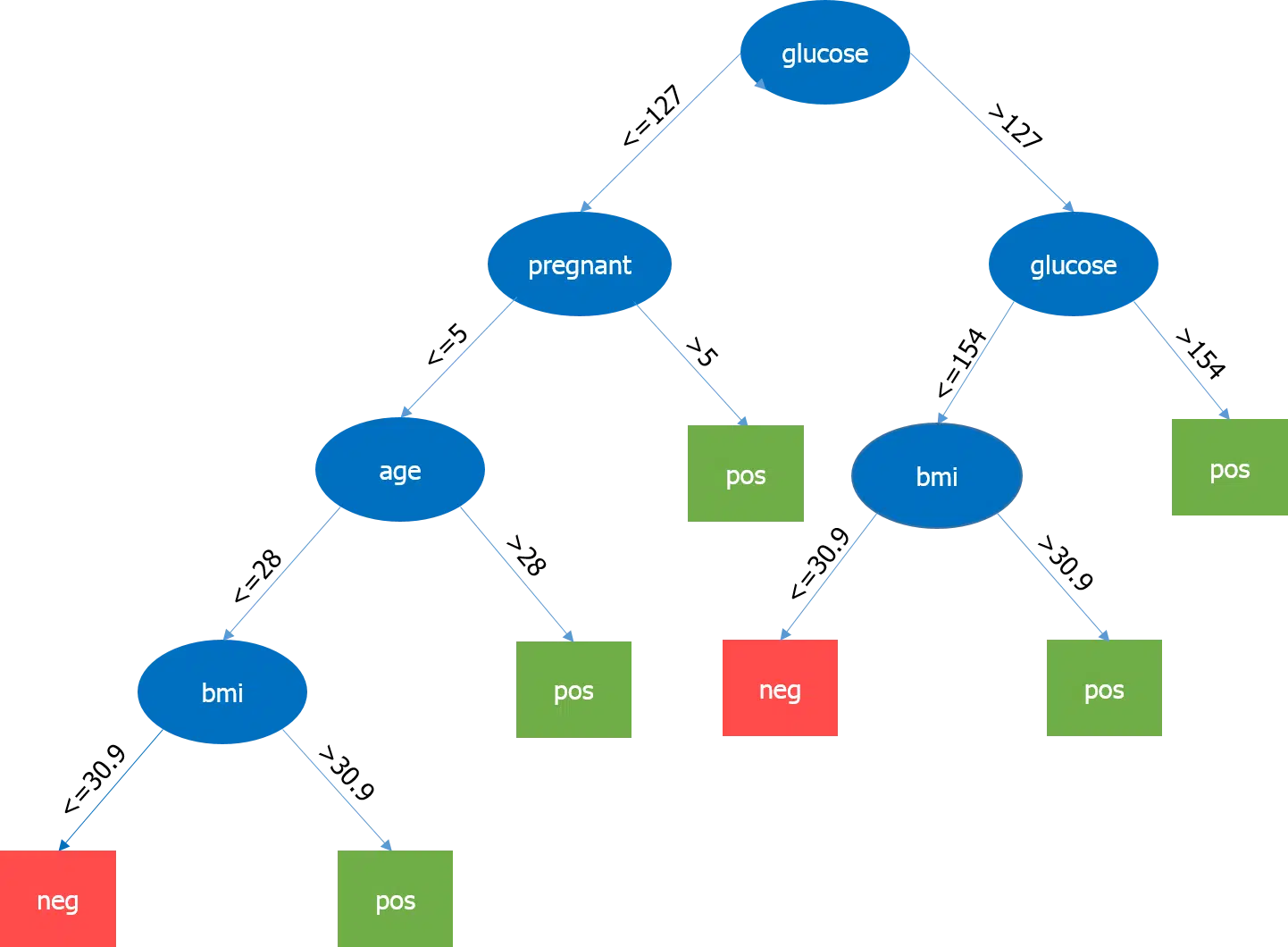
Etape #5
La cinquième phase consiste à tester un pilote pour vérifier si les résultats sont corrects, si le modèle marche, si les prédictions sont en adéquation avec les observations. Si les résultats s’avèrent non probants, le modèle devra être redéfini et reconstruit.
Découvrez les technologies web les plus utilisées en 2018.
Etape #6
Une fois que le projet a été testé et validé, il n’y a plus qu’à partager les résultats et à organiser le déploiement du modèle.
Conclusion
On ne serait pas loin de la réalité en affirmant que l’avenir appartient aux Data Scientists. D’ailleurs, de plus en plus d’entreprises sautent le pas et décident de recruter ces oiseaux (encore) rares. On estime que d’ici quelques mois (fin 2018), le nombre d’experts en Data Science dans le monde avoisinera le million. S’il y a un métier qui ne connaît pas la crise, c’est bien celui-ci.
L’augmentation continue du volume de données collectées ne cesse d’étendre les pouvoirs de la Data Science. Il n’y a aucun doute sur le fait que, de plus en plus, les grandes décisions stratégiques seront prises sur la base des modèles prédictifs développés par la Data Science. Il faut s’y faire, et surtout s’y préparer. On a encore du mal à imaginer l’impact qu’aura la Data Science sur l’économie. Mais il sera énorme, ça ne fait aucun doute.



Laisser un commentaire