



















Scrapebox est l'un des logiciels de scraping de référence. Lancé en 2009, le logiciel est constamment mis à jour pour s'adapter aux évolutions du web (plus de 400 MaJ depuis sa création). Scrapebox permet de créer des listes d'URLs et de récolter des données très variées depuis plus de 30 moteurs de recherche. Véritable "couteau suisse", Scrapebox peut servir à des usages très variés, aussi bien SEO que marketing.
Principales fonctionnalités de Scrapebox
Il est impossible de dresser la liste de toutes les fonctionnalités de Scrapebox. Elles sont quasiment infinies. Scrapebox est un logiciel de scraping. Le scraping (ou Harvesting, Harvest signifiant « récolte » en anglais) est une technique bien connue des Growth Hackers. Elle consiste à récolter des données à partir de pages web indexées dans les moteurs de recherche.
Scrapebox permet de générer des listes d’URL à partir de mots-clés et de footprints. La possibilité de spécifier les footprints et d’utiliser plusieurs mots-clés pour affiner la recherche est l’un des grands avantages de Scrapebox. Vous pouvez générer des liste d’URLs à partir de plusieurs mots-clés ou requêtes.
Voici un schéma pour bien comprendre le fonctionnement de Scrapebox :

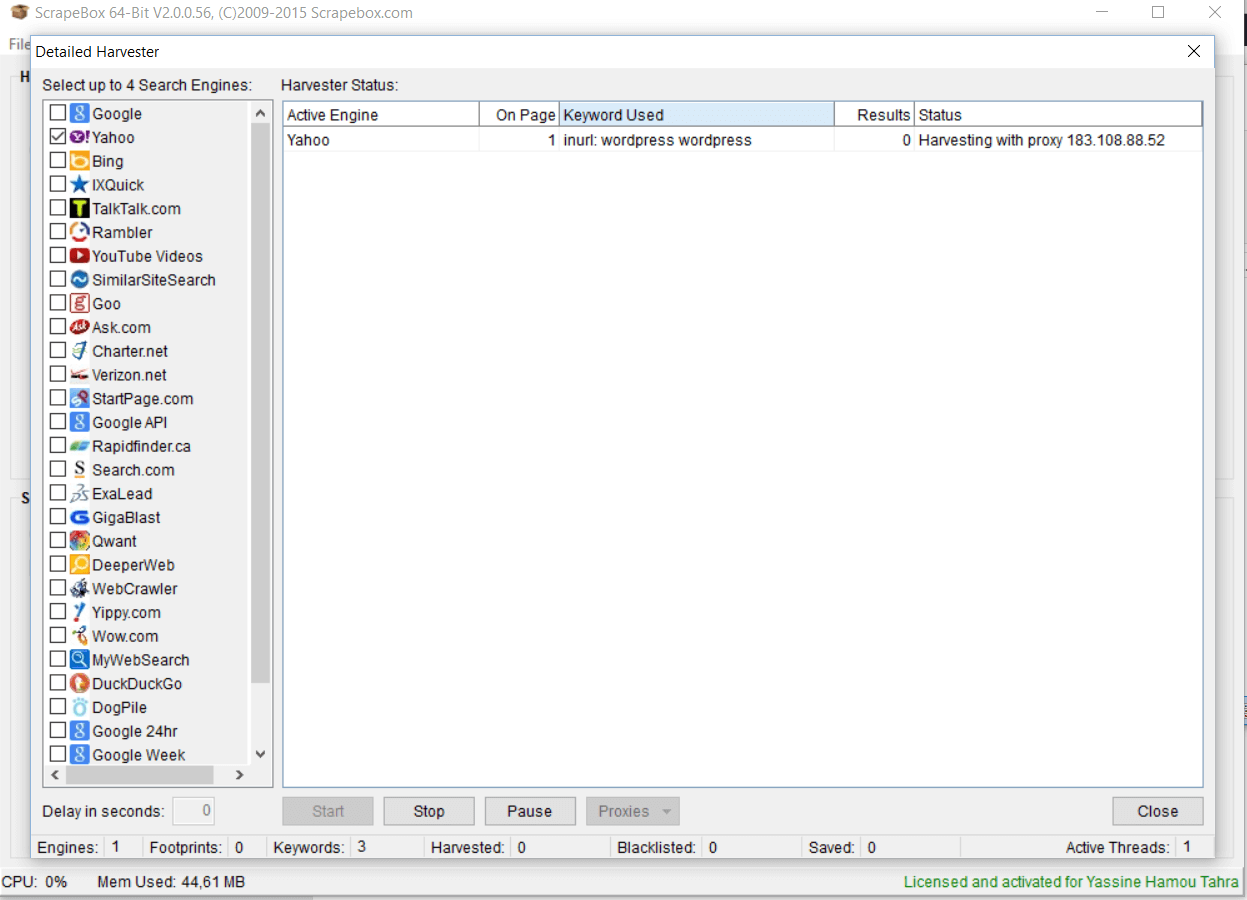
Ce schéma permet de bien comprendre le fonctionnement général de Scrapebox. Dans un premier temps, vous devez chercher et tester des proxies. Un proxy serveur sert d’interface entre votre ordinateur et internet. Lorsqu’on fait du scraping, il est indispensable d’utiliser plusieurs proxies anonymes pour éviter de se faire blacklister par les moteurs de recherche. Une des fonctionnalités très intéressantes de Scrapebox est de permettre de trouver et tester très facilement des quantités de proxies dynamiques (le logiciel teste leur validité, le temps latence et leur anonymat). Scrapebox est sans conteste l’un des meilleurs outils pour récupérer des centaines de proxies gratuits (scraping de proxies). Vous pouvez ensuite, si vous le souhaitez, récupérer les proxies pour les utiliser à d’autres fins. Vous pouvez aussi, sur Scrapebox, tester la validité de vos propres listes de proxies.
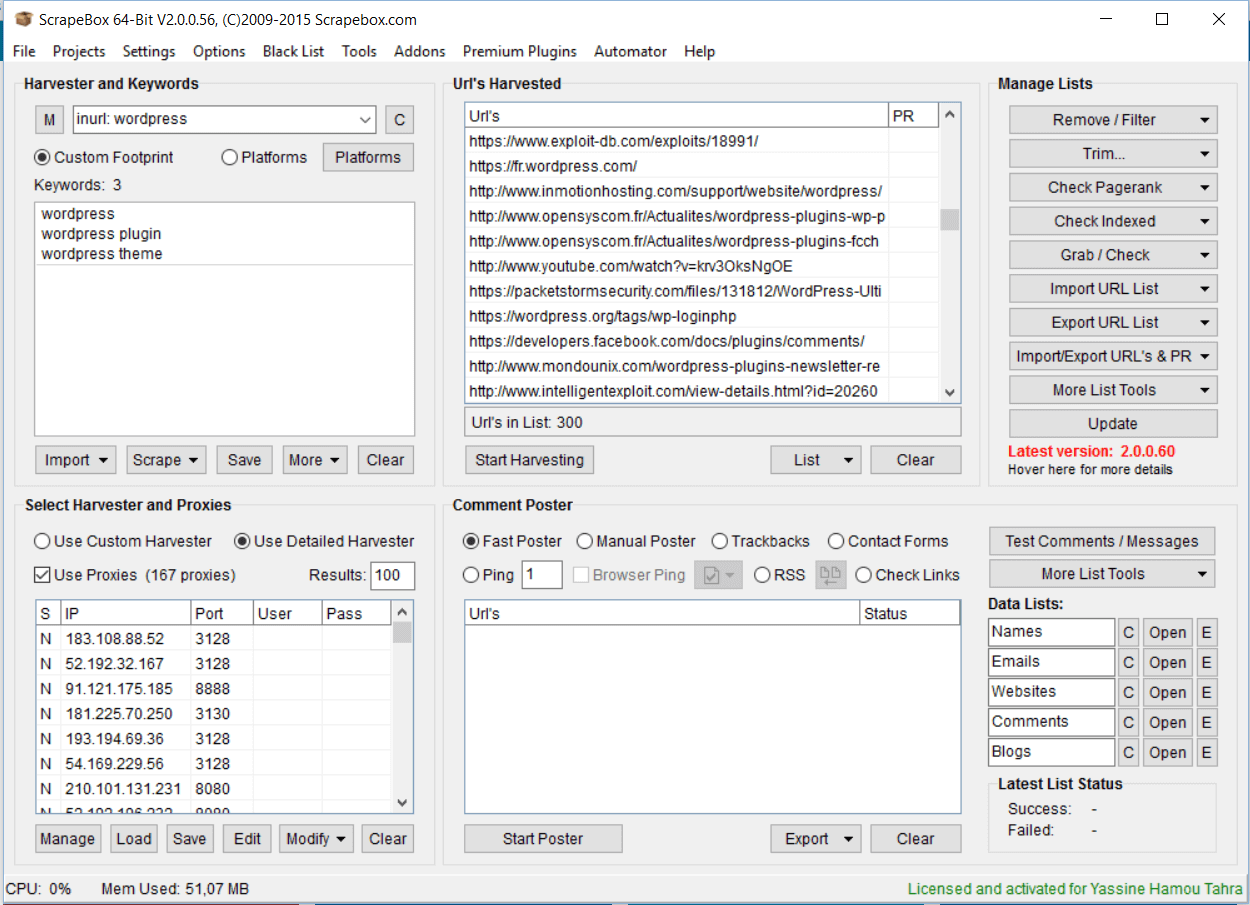
La deuxième étape consiste, comme on l’a vu, à renseigner des mots-clés et le footprint. Dans notre exemple (cf. capture d’écran), nous souhaitons récupérer des URL qui ont un lien avec la thématique WordPress/plugin/thème. Nous avons donc renseigné trois mots-clés : « wordpress », « wordpress plugin » et « wordpress theme ». Nous souhaitons aussi que le terme « wordpress » soit présent dans les URL. Nous avons donc renseigné le footprint « inurl: wordpress » (si on avait voulu uniquement des sites avec l’extension « .fr », on aurait utiliser le footprint « site: fr »). Les mots-clés se combinent avec le footprint choisi. Dans notre exemple, on veut connaître toutes les pages qui traitent des plugins wordpress ou des thèmes wordpress et qui contiennent « wordpress » dans l’URL. Une fois que l’on a rentré les mots-clés et le footprint, on lance le scraping (l’opération dure quelques secondes seulement). Scrapebox vous propose ensuite des centaines, voire des milliers d’URL.

En résumé, Scrapebox permet principalement ceci :
- Trouver des adresses de sites ou de pages qui vous intéressent, grâce à des options de recherche très fines (mots-clés/footprints).
- Sélectionner les sources du scraping parmi plus de 30 moteurs de recherche.
- Trier les URL listées par le logiciel en fonction d’un large choix de filtres (dans la box « Manage Lists »).
- Trouver des proxies gratuits ou tester la validiter de vos proxies.
- Mais aussi : identifier des noms de domaine expirés, automatiser le posting de commentaires sur les blogs, scraper des images, etc.
Comment utiliser Scrapebox concrètement ?
Toutes les pages web sont indexées par les moteurs de recherche, par définition. De cela il découle une conclusion toute simple : le scraping, qui utilise les données présentes dans les moteurs de recherche, permet de récupérer tout ce que l’on veut sur internet. C’est la raison pour laquelle les usages de Scrapebox sont quasiment infinis. Certaines (beaucoup ?) de personnes ne font pas un usage très « recommandable » de Scrapebox. De fait, Scrapebox est beaucoup utilisé pour des techniques de Black Hat SEO, c’est-à-dire des techniques SEO interdites par les moteurs de recherche (notamment le posting automatique de commentaires de blog, à partir de la box « Comment Poster », dont il n’est pas question dans cette fiche). Pour en savoir plus, nous vous invitons à lire notre article sur les pratiques dangereuses en SEO. Pour vous donner une petite idée des potentialités de Scrapebox, nous vous proposons quatre techniques « propres » ou « White Hat ».
Cibler de potentiels backlinks
Qui dit SEO dit recherche de backlinks. Sur Scrapebox, il est possible d’identifier rapidement et facilement des centaines d’URL de sites pertinents pour vos backlinks. Si par exemple vous avez écrit un article sur les plugins et les thèmes WordPress et que vous souhaitez générer des backlinks sur cet article, tapez « WordPress », « WordPress theme » et « WordPress plugin » dans la zone de mots-clés (voir la capture d’écran ci-dessus). Sélectionnez les moteurs de recherche et choisissez vos proxies. Ensuite, lancez le scraping en cliquant sur « Start Harvesting ». Scrapebox liste les URL qui correspondent à ces mots-clés. Vous pouvez ensuite filtrer les URL par PR pour ne garder que les pages pertinentes (aux yeux des moteurs de recherche…). Cela vous permettra par exemple de ne retenir que les pages dont le PR est égal ou supérieur à 3. Exportez enfin votre liste d’URL et contactez les webmasters (pour cela, lire le paragraphe suivant). Scrapebox permet de générer simplement des listes d’URL de blogs ou de sites internet intéressants pour votre stratégie de backlinks.
Le petit plus : il est possible de trier les pages en Do Follow / No Follow. Pour rappel, un backlink en Do Follow a beaucoup plus de poids qu’un lien en No Follow. Certains footprints sont très utiles pour trouver des URL de sites à partir desquels générer des backlinks. Notamment : « intitle:resources », « inurl:resources » et « inurl:links » : ces footprint permettent d’identifier les pages sur lesquelles les sites placent beacuoup de liens externes. Vous l’aurez peut-être compris : pour tirer le meilleur profit de Scrapebox, vous devez :
- Trouver les bons mots-clés et les bons footprints pour générer des listes d’URL pertinentes.
- Filtrer de manière intelligente les listes d’URL générées par Scrapebox à l’aide de la box « Manage Lists ».
- Faire un bon usage de ces URL. Les paragraphes suivants montrent plsuieurs usages possibles.
Générer des emails (scraping d’emails)
Scrapebox est un outil très efficace pour scraper des adresses emails. Plusieurs techniques sont possibles. En voici une : vous pouvez générer, à partir des noms de domaine, des adresses emails sous la forme « contact@nomdedomaine ». La technique est simple : vous générez une liste d’URL à partir de mots-clés et d’un footprint bien choisis. Vous filtrez les URL pour ne retenir que les noms de domaine. Vous exportez la liste d’URL filtrée. Vous générez des adresses emails « contact@nomdedomaine » à partir de votre fichier d’URL. Bien sûr, tous les sites n’ont pas d’adresse email en « contact@nomdedomaine ». Vous devez donc supprimer les adresses emails invalides. Pour cela, vous pouvez utiliser un logiciel comme Listwise. Ce logiciel vous permettra de tester automatiquement la validité des adresses emails générées à partir du pattern « contact@nomdedomaine ».
Repérer les blogs infectés par les malwares
Voici une technique assez originale, qui illustre bien l’infinité des usages que l’on peut faire de Scrapebox. Cette technique peut être résumée très simplement :
- Vous listez les URL de blogs infectés par des malwares. Il y en a des centaines et des centaines.
- Vous envoyez un mail aux bloggeurs concernés en leur expliquant que leur site est infecté.
- Vous leur demandez quelque chose en échange (sinon, la technique n’a pas d’intérêt !). La monnaie d’échange en l’occurrence, c’est principalement le backlink (SEO oblige).
Pour générer des listes d’URL de blogs infectés, vous ne pourrez pas utiliser de footprints générales (du type « site:malwares » !). Par contre, certains CMS constituent une cible privilégiée pour les hackers. L’idée est d’identifier ces CMS et de retrouver les blogs qui l’utilisent via des footprints spécifiques à ces CMS. Neil Patel, sur son blog, donne un exemple de CMS très vulnérable : il s’agit de Pligg. Les footprints qui permettent de trouver les sites qui utilisent ce CMS sont « inurl:story.php?title= » et « Five character minimum ». A vous d’identifier les éléments qui constituent des marques de fabrique des CMS (pour WordPress : « Powered By : WordPress » par exemple).
Une fois que vous avez la liste d’URL, utilisez le filtre de malware et de phishing disponible sur Scrapebox (vous devez installer l’addon). Ce filtre vous permettra de détecter tous les sites qui sont victimes d’un malware ou d’un phishing. Sélectionnez l’option « Save Bad URL’s to File » et exportez la liste d’URL filtrée. Pour récupérer les adresses contact de ces blogs infectés, vous pouvez par exemple utiliser le plugin de ScrapeBox « Whois Scraper ». L’idée, c’est d’éviter d’avoir à vous rendre sur les blogs en question et de vous faire vous-même infecter. Vous pouvez aussi récupérer les adresses contact à l’aide de l’astuce présentée dans le paragraphe précédent.
Une fois que vous avez récupéré les adresses mails des bloggeurs ou des webmasters de sites infectés, contactez-les et informez-les que leur site est infecté. Ensuite, demandez-leur un backlink en échange de votre diagnostic ! C’est une technique astucieuse pour générer des backlinks.
Identifier des requêtes SEO
Vous pouvez, sur Scrapebox, identifier une série de requêtes rattachée à un groupe de mots-clés. Pour cela, rendez-vous dans « Harvester » ==> « Scrape » ==> « Keyword Scraper ». Il suffit de renseigner plusieurs mots-clés en lien avec les requêtes que vous aimeriez trouver. ScrapeBox vous propose des centaines, voire des milliers de résultats intégrant les mots-clés/ thématiques pré-définis. C’est très utile pour trouver des requêtes sur lesquelles se positionner. Scrapebox complète ici les outils classique du type Google AdWords. Les résultats proposés par Scrapebox peuvent là aussi être filtrés et affinés de manière très pertinente.


Tarification de Scrapebox
Scrapebox est un logiciel sous licence. Le coût de la licence pour utiliser Scrapebox est normalement de 197 dollars, mais des promotions sont souvent proposées. Le logiciel est actuellement à 97 dollars, au lieu de 197 dollars. L’achat de la licence est définitif. Elle est valable « à vie ».
Une fois que vous avez acheté la licence de Scrapebox, vous pouvez installer gratuitement les 33 addons que propose le logiciel.
Pour obtenir plus de fonctionnalités, il est possible d’acheter des packs de plugins (à ne pas confondre avec les « addons »). Voici la grille tarifaire :

Remarque : le logiciel fonctionne uniquement sous Windows, et donc sur PC, mais il est possible de l’utiliser sur Mac en utilisant un VPS (du type : Parallels, VMWare ou BootCamp). ScrapeBox n’a pas prévu pour le moment la publication d’une version native pour Max. Pour en savoir plus sur la tarification et l’installation de Scrapebox, lire la FAQ de Scrapebox.
Avis sur Scrapebox
Les points forts :
Scrapebox est sans conteste l’un des meilleurs logiciels pour scraper, en raison de sa richesse fonctionnelle et de sa prise en main facile. Vous trouverez des centaines de tutoriels gratuits sur internet (articles + vidéos) pour approfondir votre maîtrise de Scrapebox. Voici les points forts de Scrapebox :
- Assez simple d’utilisation. On peut devenir familier de Scrapebox en quelques heures d’utilisation (ou même moins). Le process est simple : définition des mots-clés et des footprints, sélection des proxies, filtrage des URL, export de la liste filtrée.
- La possibilité de trouver et de tester des centaines de proxies
- La possibilité de générer des listes d’URL très qualifiées, grâce aux filtres.
- Les addons, gratuits, apportent des fonctionnalités supplémentaires très utiles.
Les points faibles :
Il n’y a pas vraiment de points faibles. On pourrait recherche la petite bête et regretter par exemple que le logiciel soit payant. Mais le coût du logiciel est rapidement rentabilisé. On peut aussi préciser que la prise en main du logiciel est rapide, mais demandera tout de même un peu de temps à celles et ceux qui sont encore novice en scraping.

Acheté en promo pour $57 en 2010 a sa sortie, meilleur investissement de ma vie (:
Bonjour,
Il y a une remise sur le tool qui passe à 67$ au lieu de 97$ à l’URL suivante : http://www.scrapebox.com/bhw
Merci pour le partage de la réduction ! Elle est encore valable plusieurs mois après ton commentaire
Merci pour cette présentation je ne connaissais pas du tout scrapebox, est il toujours possible de l’acheté encore aujourd’hui?
Bien cordialement
Oui, toujours disponible à l’achat. La version 2 est en bêta semble-t-il.
Bonjour ,
J’ai acheté scrapebox il y a des années de cela je suis super content de le ressortir des oubliettes. Je ne l’utilisais plus mais là pour mon site web je me suis dit allez on ressort tout l’attirail seo de l’ordinateur pour ranker un Max sur les mots clés. Après tant d’années je trouve le logiciel toujours aussi performant. J’adore la partie suggestions de mots clés . Cela donne plein d’idées pour des faq ou améliorer son texte.
Merci pour cette présentation intéressante !
Est-il possible de faire un tri des urls obtenue en fonction de la langue ? Par exemple trier uniquement les résultats en français?
Merci à vous !
Nicolas
Pas à ma connaissance.
Je ne crois pas qu’il existe par défaut un filtre « langue » mais il devrait être possible de récupérer l’attribut « lang » de la balise html de chaque URL avec des outils de scrapping plus souples comme Octoparse ou Parsehub.